
Apigee API Management
Manage APIs with unmatched scale, security, and performance
Google Cloud’s native API management tool to build, manage, and secure APIs—for any use case, environment, or scale.
Explore Apigee for free in your own sandbox for 60 days.
Jumpstart your development with helpful resources.

Features
Using Gemini Code Assist in Apigee API Management
Create consistent quality APIs without any specialized expertise. You can create new API specifications with prompts in Apigee plugin, integrated into Cloud Code. In Apigee, Gemini Code Assist considers your prompt and existing artifacts such as security schema or API objects, to create a specification compliant with your enterprise. You can further slash development time by generating mock servers for parallel development and collaborative testing. Lastly, Gemini also assists you in turning your API specifications into proxies or extensions for your AI applications.

Universal catalog for your APIs
Consolidate API specifications—built or deployed anywhere—into API hub. Built on open standards, API hub is a universal catalog that allows developers to access APIs and govern them to a consistent quality. Using autogenerated recommendations provided by Gemini, you can create assets like API proxies, integrations, or even plugin extensions that can be deployed to Vertex AI or ChatGPT.

Automated API Security with ML based abuse detection
Advanced API Security detects undocumented and unmanaged APIs linked to Google Cloud L7 Load Balancers. Advanced API Security also regularly assesses managed APIs, surfaces API proxies that do not meet security standards, and provides recommended actions when issues are detected. ML-powered dashboards accurately identify critical API abuses by finding patterns within the large number of bot alerts, reducing the time to act on important incidents.

High-performance API proxies
Orchestrate and manage traffic for demanding applications with unparalleled control and reliability. Apigee supports styles like REST, gRPC, SOAP, and GraphQL, providing flexibility to implement any architecture. Using Apigee, you can also proxy internal microservices managed in a service mesh as REST APIs to enhance security.

Hybrid/multicloud deployments
Achieve the architectural freedom to deploy your APIs anywhere—in your own data center or public cloud of your choice—by configuring Apigee hybrid. Host and manage containerized runtime services in your own Kubernetes cluster for greater agility and interoperability while managing APIs consistently with Apigee.

Traffic management and control policies
Apigee uses policies on API proxies to program API behavior without writing any code. Policies provided by Apigee allow you to add common functionality like security, rate limiting, transformation, and mediation. You can configure from a robust set of 50+ policies to gain control on behavior, traffic, security, and QoS of every API. You can even write custom scripts and code (such as JavaScript applications) to extend API functionality.

Developer portals integrated into API life cycle
Bundle individual APIs or resources into API products—a logical unit that can address a specific use case for a developer. Publish these API products in out-of-the-box integrated developer portals or customized experiences built on Drupal. Drive adoption of your API products with easy onboarding of partners/developers, secure access to your APIs, and engaging experiences without any administrative overhead.

Built-in and custom API analytics dashboards
Use built-in dashboards to investigate spikes, improve performance, and identify improvement opportunities by analyzing critical information from your API traffic. Build custom dashboards to analyze API quality and developer engagement to make informed decisions.

Near real-time API monitoring
Investigate every detail of your API transaction within the console or in any distributed tracing solution by debugging an API proxy flow. Isolate problem areas quickly by monitoring their performance or latency. Use Advanced API Operations to identify anomalous traffic patterns and get notified on unpredictable behaviors without any alert fatigue or overheads.

API monetization
Create rate plans for your API products to monetize your API channels. Implementing business models of any complexity by configuring billing, payment model, or revenue share with granular details.

Options table
| Product | Description | When to use this product? |
|---|---|---|
Fully managed comprehensive solution to build, manage, and secure APIs—for any use case or scale | Managing high value/volume of APIs with enterprise-grade security and dev engagement | |
Comprehensive API management for use in any environment—on-premises or any cloud | Maintaining and processing API traffic within your own kubernetes cluster | |
Customer managed service to run co-located gateway or private networking | Managing gRPC services with locally hosted gateway for private networking | |
Fully managed service to package serverless functions as REST APIs | Building proof-of-concepts or entry-level API use cases to package serverless applications running on Google Cloud |
Learn which Google Cloud solution is appropriate for your use case here.
Fully managed comprehensive solution to build, manage, and secure APIs—for any use case or scale
Managing high value/volume of APIs with enterprise-grade security and dev engagement
Comprehensive API management for use in any environment—on-premises or any cloud
Maintaining and processing API traffic within your own kubernetes cluster
Customer managed service to run co-located gateway or private networking
Managing gRPC services with locally hosted gateway for private networking
Fully managed service to package serverless functions as REST APIs
Building proof-of-concepts or entry-level API use cases to package serverless applications running on Google Cloud
Learn which Google Cloud solution is appropriate for your use case here.
How It Works
Apigee provides an abstraction or facade for your backend services by fronting services with API proxies. Using these proxies you can control traffic to your backend services with granular controls like security, rate limiting, quotas, and much more.

Common Uses
Cloud-first application development
Use APIs to build modern applications and architectures
Use APIs to build modern applications and architectures
Build API proxies that enable your applications to access data and functionality from your Google Cloud back end or any system, service, or application. Scale your applications based on demand using load balancing for your APIs. As you scale, you can unlock greater business agility by decoupling your monolithic application into microservices.

Tutorials, quickstarts, & labs
Use APIs to build modern applications and architectures
Use APIs to build modern applications and architectures
Build API proxies that enable your applications to access data and functionality from your Google Cloud back end or any system, service, or application. Scale your applications based on demand using load balancing for your APIs. As you scale, you can unlock greater business agility by decoupling your monolithic application into microservices.
Modernize legacy apps and architectures
Package legacy applications using RESTful interfaces

Learning resources
Package legacy applications using RESTful interfaces
New business channels and opportunities
Publish and monetize your API products in developer portals
Publish and monetize your API products in developer portals
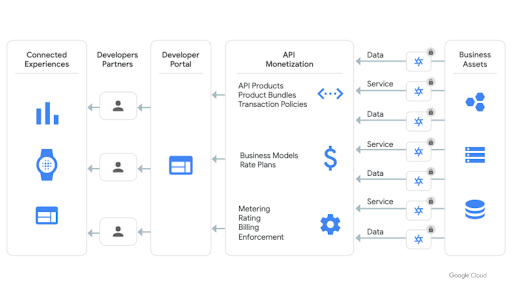
Consolidate APIs built anywhere into a single place to enable easy access for developers with API hub. Package multiple APIs or methods into API products to drive consumption. Publish these API products in developer portals to onboard partners or customer developers. Define comprehensive rate plans to monetize your API product consumption with any business model.
Tutorials, quickstarts, & labs
Publish and monetize your API products in developer portals
Publish and monetize your API products in developer portals
Consolidate APIs built anywhere into a single place to enable easy access for developers with API hub. Package multiple APIs or methods into API products to drive consumption. Publish these API products in developer portals to onboard partners or customer developers. Define comprehensive rate plans to monetize your API product consumption with any business model.
Uniform hybrid or multicloud operations
Operate in any environment with consistency
Operate in any environment with consistency
Use APIs to expose services that are distributed across any environment—private data centers or public clouds. With Apigee hybrid, you can host containerized runtime services in your own K8S cluster to blend your legacy and existing systems with ease. This way, you can adhere to compliance and governance requirements—while maintaining consistent control over your APIs and the data they expose.

Tutorials, quickstarts, & labs
Operate in any environment with consistency
Operate in any environment with consistency
Use APIs to expose services that are distributed across any environment—private data centers or public clouds. With Apigee hybrid, you can host containerized runtime services in your own K8S cluster to blend your legacy and existing systems with ease. This way, you can adhere to compliance and governance requirements—while maintaining consistent control over your APIs and the data they expose.
Web application and API security
Implement security in multiple layers with advanced controls
Implement security in multiple layers with advanced controls
Security is top priority today. Google Cloud launched WAAP (Web App and API Protection) based on the same technology Google uses to protect its public-facing services against vulnerabilities, DDoS attacks, fraudulent bot activity, and API-targeted threats. It combines three solutions (Apigee, Cloud Armor, and reCAPTCHA Enterprise) to provide comprehensive protection against threats.

Tutorials, quickstarts, & labs
Implement security in multiple layers with advanced controls
Implement security in multiple layers with advanced controls
Security is top priority today. Google Cloud launched WAAP (Web App and API Protection) based on the same technology Google uses to protect its public-facing services against vulnerabilities, DDoS attacks, fraudulent bot activity, and API-targeted threats. It combines three solutions (Apigee, Cloud Armor, and reCAPTCHA Enterprise) to provide comprehensive protection against threats.
Pricing
| How Apigee pricing works | Apigee offers 3 flexible pricing options—evaluation, pay-as-you-go, and subscription—to suit any API management needs | |
|---|---|---|
| Pricing model | Description | Price (USD) |
Evaluation | Experience industry-leading API management capabilities in your own sandbox at no cost for 60 days | Free |
Pay-as-you-go | API calls Charged on the volume of API calls processed by the API proxy you deployed. Apigee provides the ability to deploy 2 types of proxies: Standard API Proxy Extensible API Proxy | Starting at $20 Up to 50M API calls (per 1M API calls) |
Environments Charged on the usage of deployment environments per hour per region. Apigee provides access to 3 types of environments: Base Intermediate Comprehensive | Starting at $365 per month per region | |
Proxy deployments Charged on the number of API proxies/shared flows deployed to an environment. Additional deployments are available for purchase only in Comprehensive environments | $0.04 per hour per region | |
Add-ons Choose and pay for additional capacity or capabilities per your requirements. Using Pay-as-you-go pricing, you can add the following: API Analytics Advanced API Security | Starting at $20 per 1M API calls | |
Subscription | Standard To start building your enterprise-wide API program Enterprise For high volume of APIs and engaging partners/developers Enterprise Plus For an API-first business with a thriving ecosystem | for a custom quote or any further questions |
Check out this pricing page for further details.
How Apigee pricing works
Apigee offers 3 flexible pricing options—evaluation, pay-as-you-go, and subscription—to suit any API management needs
Evaluation
Experience industry-leading API management capabilities in your own sandbox at no cost for 60 days
Free
Pay-as-you-go
API calls
Charged on the volume of API calls processed by the API proxy you deployed. Apigee provides the ability to deploy 2 types of proxies:
Standard API Proxy
Extensible API Proxy
Starting at
$20
Up to 50M API calls (per 1M API calls)
Environments
Charged on the usage of deployment environments per hour per region. Apigee provides access to 3 types of environments:
Base
Intermediate
Comprehensive
Starting at
$365
per month per region
Proxy deployments
Charged on the number of API proxies/shared flows deployed to an environment.
Additional deployments are available for purchase only in Comprehensive environments
$0.04
per hour per region
Add-ons
Choose and pay for additional capacity or capabilities per your requirements. Using Pay-as-you-go pricing, you can add the following:
API Analytics
Advanced API Security
Starting at
$20
per 1M API calls
Subscription
Standard
To start building your enterprise-wide API program
Enterprise
For high volume of APIs and engaging partners/developers
Enterprise Plus
For an API-first business with a thriving ecosystem
Check out this pricing page for further details.
Pricing calculator
Custom Quote
Start your proof of concept
Explore Apigee in your own sandbox
Start using Apigee with no commitment
Build your first API proxy on Apigee today
Explore helpful resources and examples
Join our Google Cloud Innovator community
FAQ
Why is an API used?
APIs enable seamless communication between applications, servers, and users in today's tech-driven world. As their numbers grow, API management has become crucial, encompassing design, development, testing, deployment, governance, security, monitoring, and monetization within the software development life cycle.
What is a RESTful API?
RESTful APIs adhere to REST (Representational State Transfer) architecture constraints. Following these architecture constraints enables APIs to offer scalability, speed, and data versatility. An API of this kind accesses data by using HTTP requests and is the most common type of API used in modern applications today.
What makes Apigee different from other API management solutions?
Apigee is Google Cloud’s fully managed API management solution. Trusted by enterprises across the globe, Apigee is developer-friendly and provides comprehensive capabilities to support diverse API architectural styles, deployment environments, and use cases. Apigee also provides flexible pricing options for every business to get started and become successful on the platform.
Which API protocols does Apigee support?
Apigee currently supports REST, SOAP, GraphQL, gRPC, or OpenAPI protocols.
Why should you secure your APIs?
Companies worldwide rely on application programming interfaces, or APIs, to facilitate digital experiences and unleash the potential energy of their own data and processes. But the proliferation and importance of APIs comes with a risk. As a gateway to a wealth of information and systems, APIs have become a favorite target for hackers. Due to the prevalence of such attacks, there is a need for a proactive approach to secure APIs.
What makes an API secure?
Apigee helps organizations stay ahead of security threats by offering protection in three layers:
1. Robust policies that protect every API transaction from unauthorized users.
2. Advanced API security provides automated controls to identify API misconfigurations, malicious bot attacks, and anomalous traffic patterns without overhead and alert fatigue. Web application and API security based on the same technology used by Google to protect its public-facing services against web application vulnerabilities, DDoS attacks, fraudulent bot activity, and API-targeted threats. Google Cloud WAAP combines three solutions (Apigee, Cloud Armor, and reCAPTCHA Enterprise) to provide comprehensive protection against threats and fraud.












